
The Many Moods of the Rainbow.
While messing around with the Spotify APIs I found one of the most interesting data points they offered insight into was a track’s audio features. Each song in Spotify has 18 different attributes that can be derived, displayed and utilized as a data reference. I was impressed by Spotify’s ability to seemingly quantify music and represent a song as data and I wondered how far I could experiment with this information. Using my personal interpretation of how colors correspond to mood I set out to create user playlists that group together similar sounding tracks for a personalized listening experience. This project follows a style of functional “data-driven development”, I adopt a logical strategy that allows the data to “do the heavy lifting”.
I hope you enjoy this walkthrough as much as I enjoyed making this project!
![]() If you haven’t yet, please refer to Polyjamoury for an introduction to the Project Architecture and Authorization Steps.
If you haven’t yet, please refer to Polyjamoury for an introduction to the Project Architecture and Authorization Steps.
Composing a Mood
When listening to any track I knew what color that I would categorize it, but I needed to be able to duplicate this process in my program. To get a better idea of the story that the data wanted to tell I handpicked songs that I felt properly represented each color.
Red- Fast, Angry, Passionate
Yellow- Sunny, Positive, Upbeat
Green- Mellow, Acoustic, Calm
Blue- Soothing, Slow, Sad
Pink- Feminine, Fun, Dancable
For each track I copied the song_features over to a json file using
with open('red.json', 'w') as f: f.write(json.dumps(red, indent=2))`
Here is an example of the output:
[
{
"danceability": 0.488,
"energy": 0.995,
"key": 1,
"loudness": -3.096,
"mode": 0,
"speechiness": 0.108,
"acousticness": 0.00153,
"instrumentalness": 0,
"liveness": 0.911,
"valence": 0.679,
"tempo": 90.058,
"type": "audio_features",
"id": "6HZdbb05lEXLvcmee3ZXO2",
"uri": "spotify:track:6HZdbb05lEXLvcmee3ZXO2",
"track_href": "https://api.spotify.com/v1/tracks/6HZdbb05lEXLvcmee3ZXO2",
"analysis_url": "https://api.spotify.com/v1/audio-analysis/6HZdbb05lEXLvcmee3ZXO2",
"duration_ms": 187933,
"time_signature": 4
}
]I was then able to analyze and compare the similarities between each track in relation to one another. To accurately paint the picture of the moods I wanted to explore, I then composed my constraints based on this audio information and how it corresponded with the intended mood/color. For this project I focused on 5 different attributes: danceability, energy, tempo, acousticness and valence. These are the definitions from the Spotify documentation.
| Key | Type | Description |
|---|---|---|
| Danceability | float | Danceability describes how suitable a track is for dancing based on a combination of musical elements including tempo, rhythm stability, beat strength, and overall regularity. A value of 0.0 is least danceable and 1.0 is most danceable. |
| Energy | float | Energy is a measure from 0.0 to 1.0 and represents a perceptual measure of intensity and activity. Typically, energetic tracks feel fast, loud, and noisy. For example, death metal has high energy, while a Bach prelude scores low on the scale. Perceptual features contributing to this attribute include: dynamic range, perceived loudness, timbre, onset rate, and general entropy. |
| Tempo | float | The overall estimated tempo of a track in beats per minute (BPM). In musical terminology, tempo is the speed or pace of a given piece and derives directly from the average beat duration. |
| Acousticness | float | A confidence measure from 0.0 to 1.0 of whether the track is acoustic. 1.0 represents high confidence the track is acoustic. |
| Valence | float | A measure from 0.0 to 1.0 describing the musical positiveness conveyed by a track. Tracks with high valence sound more positive (e.g. happy, cheerful, euphoric), while tracks with low valence sound more negative (e.g. sad, depressed, angry). |
Sketching out Constraints
Remember when I mentioned we were going to get into some “data-driven development”? Well buckle your seatbelts kiddos because here is the dashing dictionary that is the star of this show!
colors = {"red": {"danceability": {"min": 0, 'max': .5},
"energy": {"min": .7, 'max': 1.0},
"acousticness": {"min": 0, 'max': .4},
"tempo": {"min": 65.0, 'max': 300.0},
"valence": {"min": 0, 'max': .45}
},
"yellow": {"danceability": {"min": .45, 'max': 1.0},
"energy": {"min": .6, 'max': 1.0},
"acousticness": {"min": 0, 'max': .5},
"tempo": {"min": 60.0, 'max': 200.0},
"valence": {"min": .8, 'max': 1.0}
},
"pink": {"danceability": {"min": .7, 'max': 1.0},
"energy": {"min": .25, 'max': .8},
"acousticness": {"min": 0, 'max': .5},
"tempo": {"min": 0, 'max': 150},
"valence": {"min": .5, 'max': .85},
},
"green": {"danceability": {"min": .5, 'max': .7},
"energy": {"min": .2, 'max': .5},
"acousticness": {"min": .5, 'max': 1.0},
"tempo": {"min": 0.0, 'max': 180},
"valence": {"min": .35, 'max': .75}
},
"blue": {"danceability": {"min": 0, 'max': .48},
"energy": {"min": 0, 'max': .5},
"acousticness": {"min": .2, 'max': .8},
"tempo": {"min": 0, 'max': 180},
"valence": {"min": 0, 'max': .5}
}}Creating a Pool of Data

Next steps to implementing my algorithm called for creating a pool of data from which to draw songs to compare to my data type. Rather than just selecting from all my saved tracks, I thought it would be more interesting to instead create a pool that contained songs that I may not necessarily be acquainted with. I listen to a myriad of different musical artists and genres and I wanted that to be reflected in my playlists so I decided to take my top artist’s top songs.
def get_all_fav_artists() -> list:
st = get_saved_artists('short_term')
stitems = st['items']
mt = get_saved_artists('medium_term')
mtitems = mt['items']
lt = get_saved_artists('long_term')
ltitems = lt['items']
return append(stitems, mtitems, ltitems)
def audio_features_all_favs() -> list:
fav_artists = get_all_fav_artists()
saved_artist_uri = set(mapv(get_artist_uris, fav_artists))
# 91 different top saved artists (9/16/19)
ttrack_database = []
for artist in saved_artist_uri:
all_artist_top_songs = get_artist_top_tracks(artist)['tracks']
for song in all_artist_top_songs:
ttrack_database.append(song['uri'])
# a database that is a list
# of user's top artist's top tracks, 921 songs (9/16/19), 750 songs (10/11/19)
return ttrack_databaseI used a similar strategies as I did in Recently Added Playlist except this time I adapted the methods I used to append my short-term, medium-term, and long-term artists.
Link to Full Code for further clarification.
As of 9/16/19 this extracted 91 of my different favorite artists. After finding each artist_uri using mapv, I looped through and pulled each
artist’s top 10 songs and added each to ttrack_database. This left me with a pool of 921 songs by my most listened to artists to play with.
Down in my if __name__ == '__main__': I assigned top_artist_top_tracks = audio_features_all_favs() I found that running this section
of code took quite a while so to manage my runtime I copied it all over to a .json file all_fav_song_features.
`
A Small Side of FPS - Functional Programming Snobbery
This next part can get a little complex if you aren’t well acquainted with Functional Programming concepts so to
introduce these paradigms we are going to take a little break and step away from our Polyjamoury code for just one moment.
If you are already familiar with filter and partial than please feel free to skip down to the next
section
Alright folks, as tempted as I am to explore all the different nuances between Procedural/Imperative and Functional Programming ideologies, that is not the focus of this article. For my intents and purposes I am just going to review a couple of key concepts that may help you digest the next section of code. If you are intrigued by what you see here, I encourage you to read SICP (affectionately known as ‘The Wizard Book’) and watch this series of videos offered by MITOpenCourseWare.
Procedures as Black Box Abstractions
When working to solve a problem, a natural strategy is to break it down into smaller, more easily manageable parts. We can rely on separation of concerns to dictate the purpose of each different building block or function. Each function has one purpose or objective- and we can test this by looking at the input (i.e. parameters or arguments) and output (i.e. the return statement). By observing only the input and output we let the inner workings of our function become irrelevant.
“At that moment we are not concerned with how the procedure computes its result, only with the fact that it computes. The details of how the (function) is computed can be suppressed, to be considered at a later time. Indeed, as far as the procedure is concerned, it is not quite a procedure but rather an abstraction of a procedure, a so-called procedural abstraction. At this level of abstraction, any procedure that computes is equally good.” (Abelson, H. (1979) SICP Cambridge, MA. The MIT Press)
You can think of functions or procedures as mini robots, they have an input, an output and an intended abstract “purpose”.
Each robot that is built can operate independent of one another. This allows them to be moved or changed with each robot’s state remaining contained (i.e. no side effects).
This is referred to as immutable state and is beneficial to consider when writing large programs.
But what happens if one robot was to build a smaller robot? Or if one robot was able to pick up and use another robot? This is what a Higher Order Function does. Many useful HOF can be found in the functools module.
A Higher Order Function is a function that does at least one of the following:
- takes one or more functions as arguments
- returns a function as its result
Filter
When using filter I often refer to the function I write to “feed” to the Higher Order Function as the “predicate” function.
Let’s say you are asked to find which numbers are even when given a list of numbers [1 ,2, 3, 4]. We could use filter
to do so, but first we need to write a function to pass to filter
Note: Since python is lazy, when using filter, list must be used to display the content, otherwise your output will read <filter object at 0x7d98ab32a700>
def is_even(number): # this is the predicate function
if (number % 2) == 0:
return True
def returns_even_numbers(list_of_numbers):
even_numbers = list(filter(is_even, list_of_numbers))
return even_numbers
if __name__ == '__main__':
print(returns_even_numbers([1, 2, 3, 4]))
>>> [2, 4]Here is a visualization of the process filter is going through to return the new list [ 2, 4 ]

Get it? Got it? Good! Now let’s move on to just one more concept before getting back to the polyjamoury code.
Partial
The next relevant HOF to understand is functools. partial.
Partial creates a new version of the given function with one or more arguments already filled in.
Implementing partial in your code can allow for more flexibility in your callbacks and can make for more elegant and reusable code.
Another benefit to using partial is it’s ability to be passed in to a function as a single argument, although it carries the
weight of what could possibly be many more arguments.
def adds_some_numbers(a, b, c):
return a + b + c
def adds_10_to_some_numbers(a, b):
return adds_some_numbers(10, a, b)
if __name__ == '__main__':
print(adds_10_to_some_numbers(10, 20))
>> 40This code above does the same thing as this code below:
def adds_some_numbers(a, b, c):
return a + b + c
adds_10_to_some_numbers = partial(adds_some_numbers, 10)
if __name__ == '__main__':
print(adds_10_to_some_numbers(10, 20))
>> 40
So partial is kind of like your cool friend Greg who actually brings his own beer to the party.
The Sorting Hat
Now we have all those prerequisites sorted out we can return to the main project. So if you remember, at this point I have created a pool of song data
for my algorithm and constructed the constraints by which to sort songs into their mood color.
But how can I go about actually sorting each song and placing it into a playlist?
Well, my next step will be to create a “predicate function” so that I may be able use filter to compare the audio features
of each track to the color desired .
# predicate fn to get passed to (filter(partial(fn))
def is_song_color(color: dict, song: dict) -> bool:
if not color["danceability"]["min"] <= song["danceability"] <= color["danceability"]["max"]:
return False
elif not color["energy"]["min"] <= song["energy"] <= color["energy"]["max"]:
return False
elif not color["acousticness"]["min"] <= song["acousticness"] <= color["acousticness"]["max"]:
return False
elif not color["tempo"]["min"] <= song["tempo"] <= color["tempo"]["max"]:
return False
elif not color["valence"]["min"] <= song["valence"] <= color["valence"]["max"]:
return False
else:
return TrueAll this function does is ask the question- Does the information in this single tracks’s audio features dictionary fit within the constraints
of this color’s dictionary? If the value of a track’s danceability, energy, acousticness, tempo and valence is found to be within the set “min” and “max”
the program will return True. In other words, it is an algorithm that looks at a track’s features and asks is_song_color?
This next part is “The Sorting Hat” aspect of the program. Note: As I mentioned earlier, to manage runtime I wrote the pool of data all_song_features to a .json file.
I also created the function save_songs to copy the list of tracks of a given color over to a file titled colorsongs so I could view
each collection more clearly.
def get_song_features():
with open('json_data/all_fav_songs_features.json') as f:
all_fav_songs_features = json.load(f)
return all_fav_songs_features
def create_color_data(color: str) -> list:
all_fav_songs_features = get_song_features()
colorsongs = list(filter(partial(is_song_color, colors[color]), all_fav_songs_features.values()))
return colorsongs
def save_songs(colorsongs):
with open('colorsongs.json', 'w') as f:
f.write(json.dumps(colorsongs, indent=2))
return colorsongs
if __name__ == '__main__':
colorsongs = create_color_data("red")
save_songs(colorsongs)
When create_color_data is run with the selected color passed in as an argument, it will return a list of the tracks that fit within the
constraints of that particular color. Here is a little lucidchart I whipped up as a visual representation of the steps filter and partial
are going through. Consider it a psuedo-color-coded step through for your viewing pleasure.

Now that I have a list of tracks that fit within each given color, my last step to seal the deal is to
extract out each track_uri and add the tracks to a playlist!
def create_color_pl(colorsongs: list, title: str) -> None:
pl_id = create_playlist(title)
playlist = []
for song in colorsongs:
song_uris = get_artist_uris(song)
playlist.append(song_uris)
add_tracks_to_playlist(pl_id, playlist)
return None
if __name__ == '__main__':
colorsongs = create_color_data("red")
save_songs(colorsongs)
create_color_pl(colorsongs,"red")
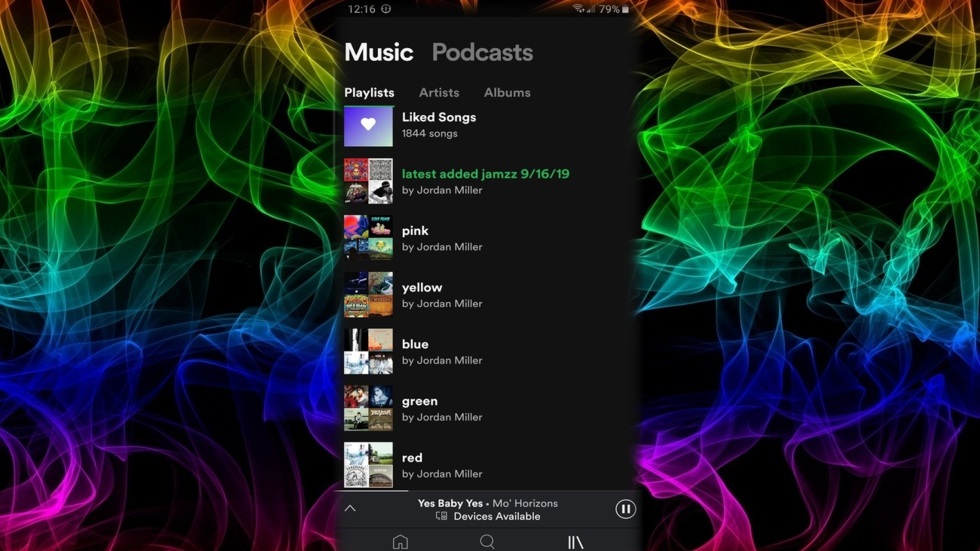
After this code is run I was able to spin up spotify on my phone and view my new playlists. After listening to all my playlists I think I have determined that my favorite color of this round of the rainbow would probably be yellow. (If you would like to follow it on spotify the link is here) One of the great things about this project is the fact that as time goes on, if I run the program again the results change and adapt to my recent listening habits. I look forward to tweaking the algorithm and recording different playlists over time.
Victory Dance!!

And that’s it! I hope that you were able to follow along and enjoy this project as much as I have! If you have stuck through it this long Congratulations and thank you for sticking with me. I hope to put out some more articles soon on “How to set up a jekyll site on a remote server using Google Cloud Services” and a more personal story- “Journey to Coding Enjoyment”.
TODO and Roadmap
- Right now the program still requires the user to pass in both the color and the title of the playlist to be created. I would like to eventually streamline this process.
- I would also like to play around with the different collections of data to “pool” from and the constraints in the algorithm.